We’re currently experiencing intermittent issues due to an outage with our cloud provider. Our team is actively monitoring the situation and working to minimize any disruptions. Thank you for your patience.
Trade smarter, comply with confidence
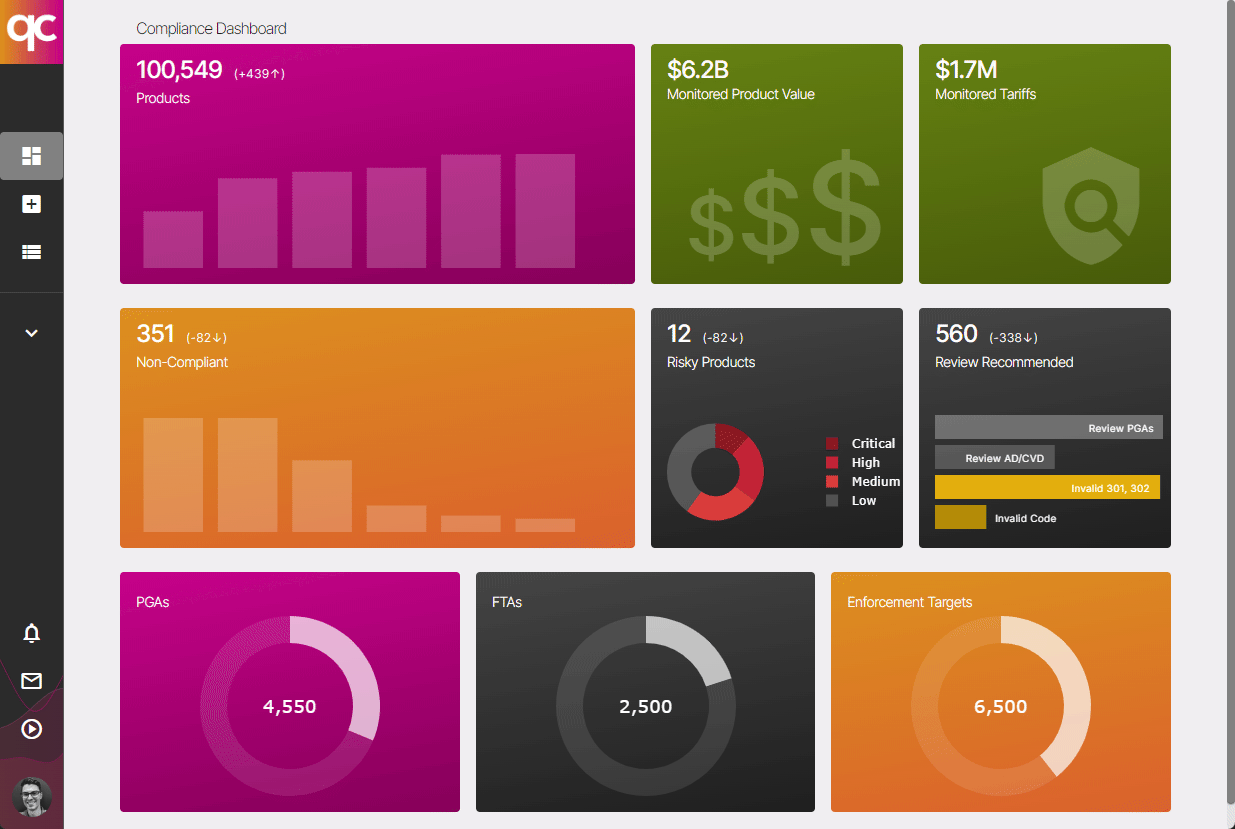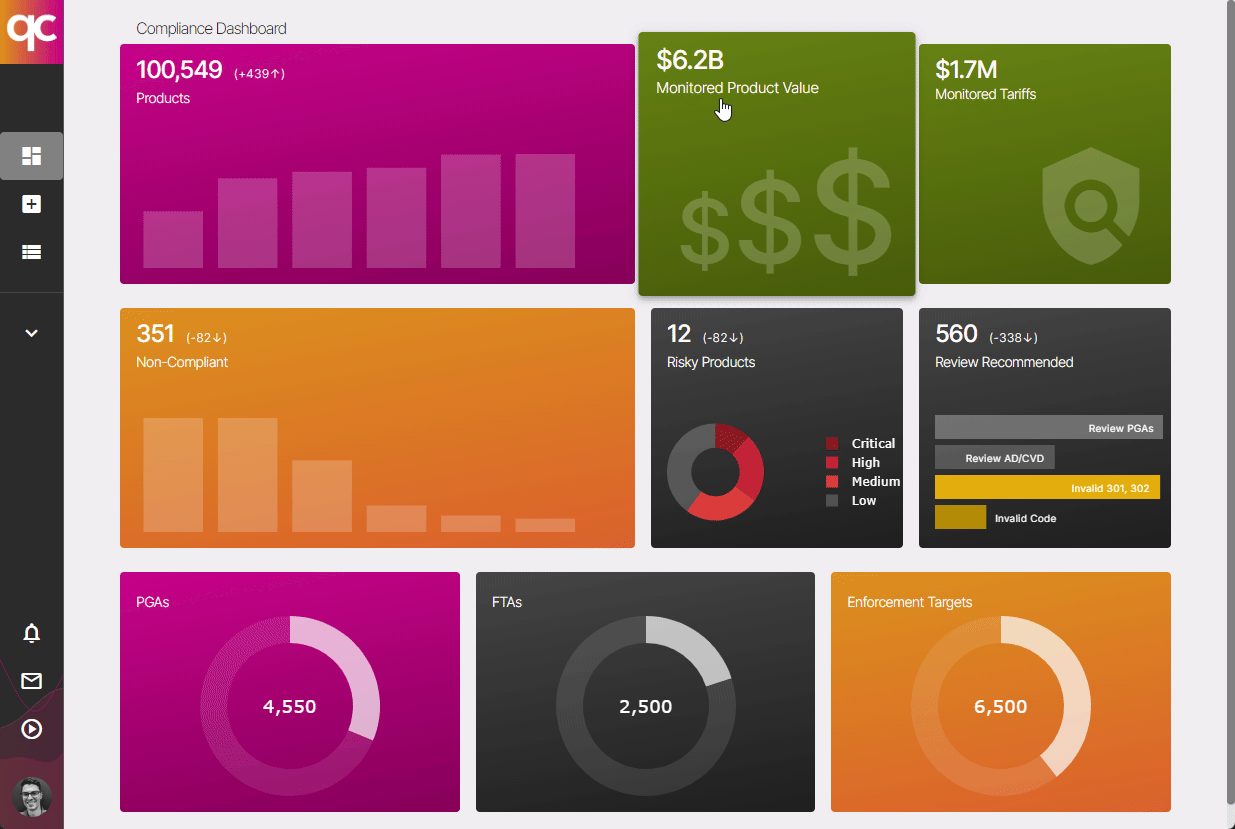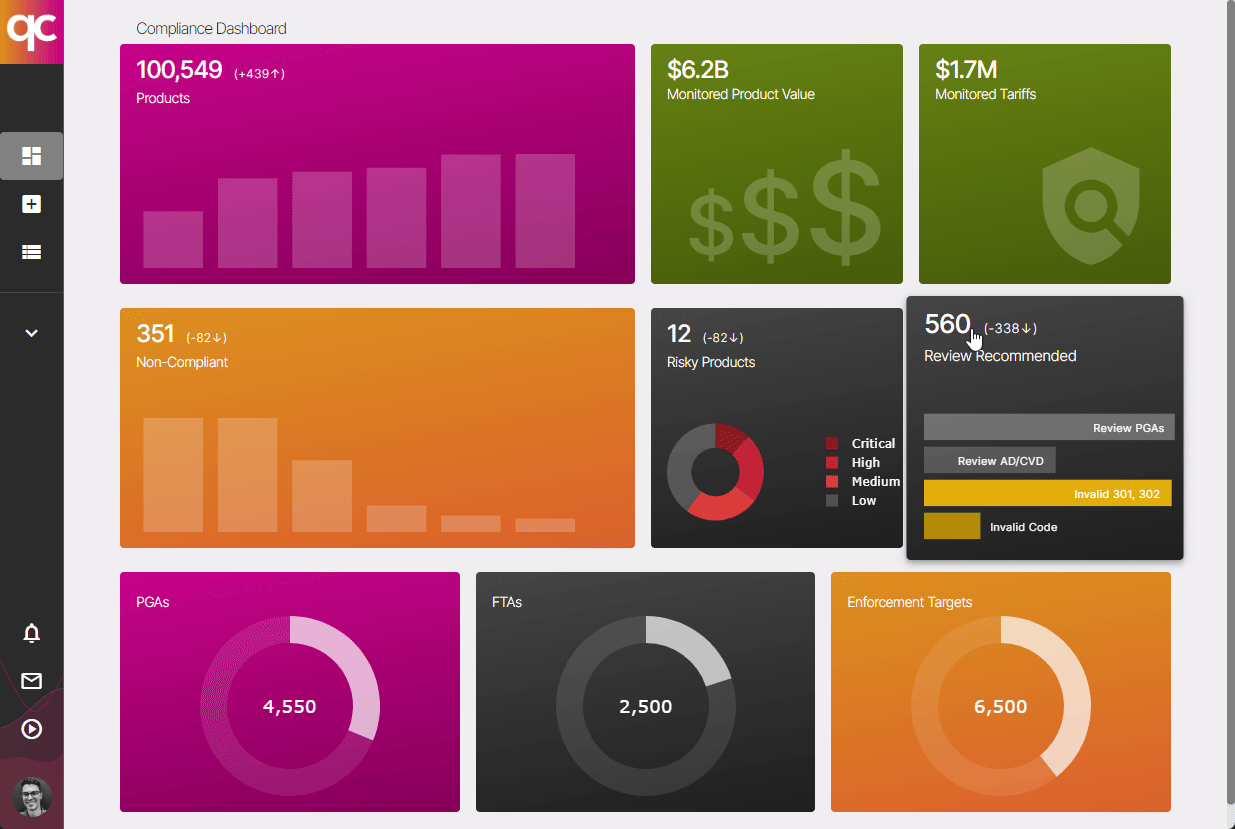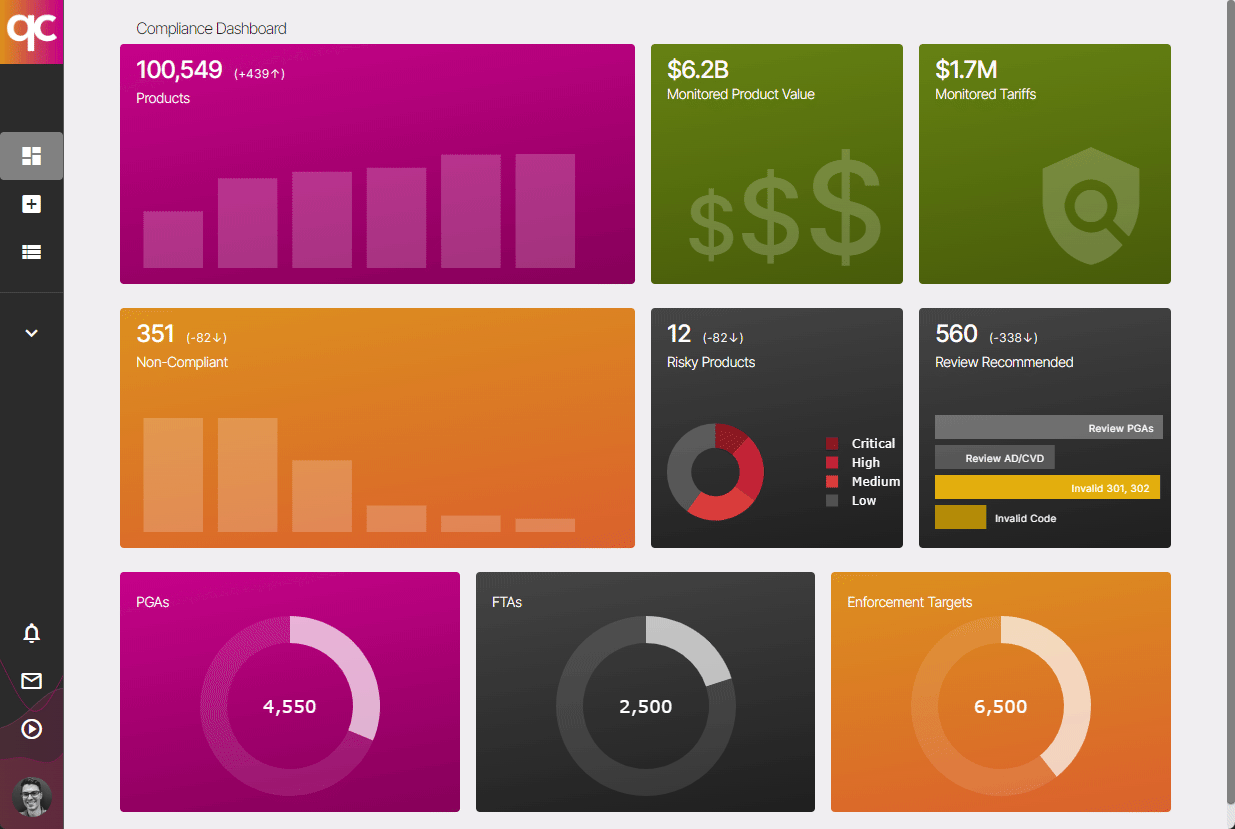
Stay ahead of tariffs. Monitor your product database. Simplify compliance.
Quickcode gives compliance teams real-time visibility into tariff changes, product codes, and regulatory risks.
Award-winning software for manufacturers, importers, and all trade compliance professionals
Winner
Winner
Winner
You’re the expert, we’re the guide
Quickcode’s AI is purpose-built for Trade Compliance workflows, helping experts keep their product catalogs in compliance with less time and effort.
Always Up-to-Date
24/7
CROSS adds new rulings daily, USITC updates tariffs often, and major regulations change too! Stay compliant, automatically!
Risk Reduced
30%
Detect misclassified products, and stay up-to-date on 301 and 232 tariffs, Partner Government Agencies (PGAs), Antidumping/Countervailing cases, and more.
Time Saved
80%
We put all your compliance resources in one screen, with AI guidance to focus on what matters.
Sign up for free, upload a sample of your product catalog, and see for yourself what compliance risks Quickcode can help you identify!
Quickcode is proud to be a member of the following organizations:
Partner
Quickcode is quick and accurate. It is very efficient to have one window into all relevant notes and rulings, and allows you to easily produce a complete classification report. Utilizing Quickcode feels like adding a new teammate to your Compliance Team.
Josh Eddie
LCB, 20 year classifier
I’ll be using Quickcode wherever I go. It is an amazing tool that I swear by.
Corey Butler
LCB, Ware Ind.
Quickcode improves efficiency by dramatically reducing the time to classify and delivering the necessary compliance data all in one place. The Compliance Monitoring dashboard makes it easy to see what needs review.
Olga Grishin
Director of Logistics, Wormser Group
Trade Compliance Software, Reimagined
Purpose-built for Trade Compliance Workflows
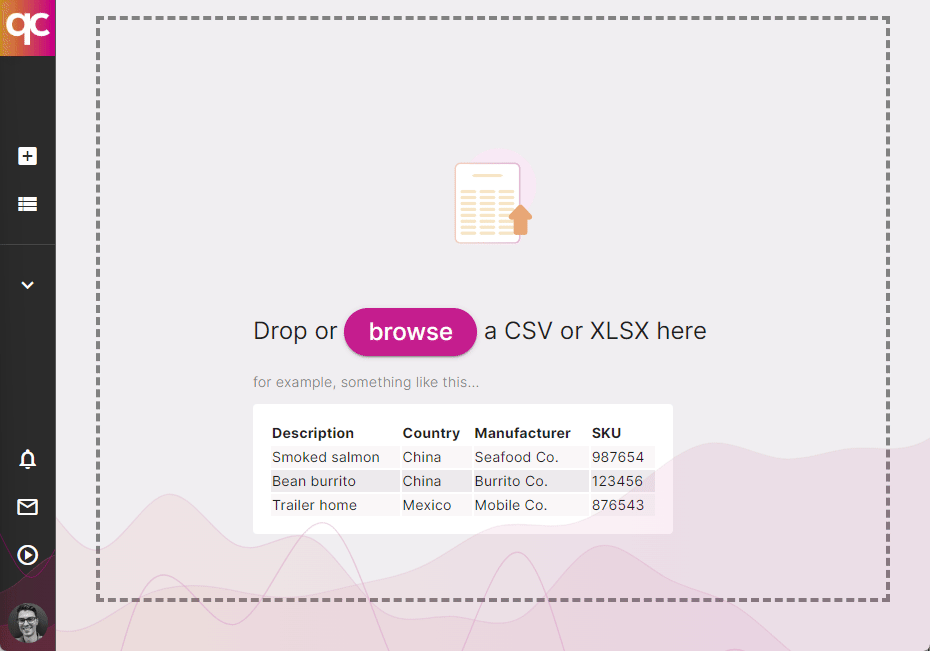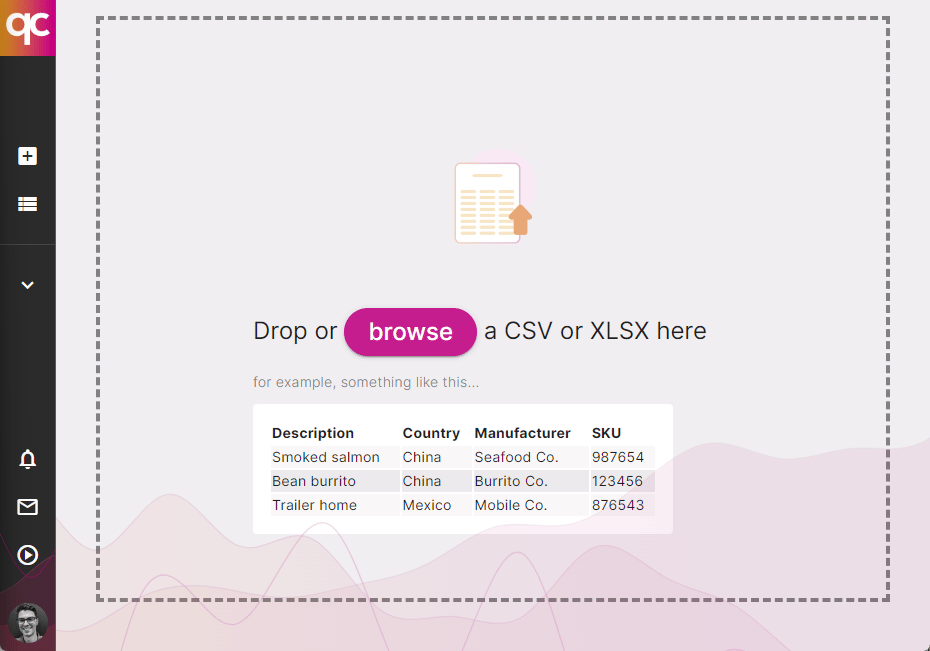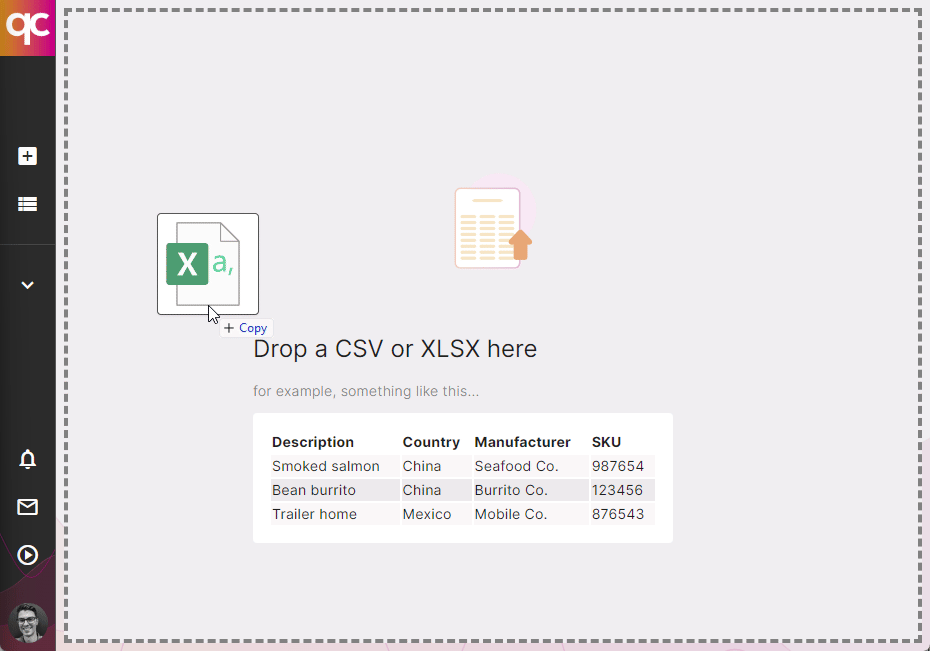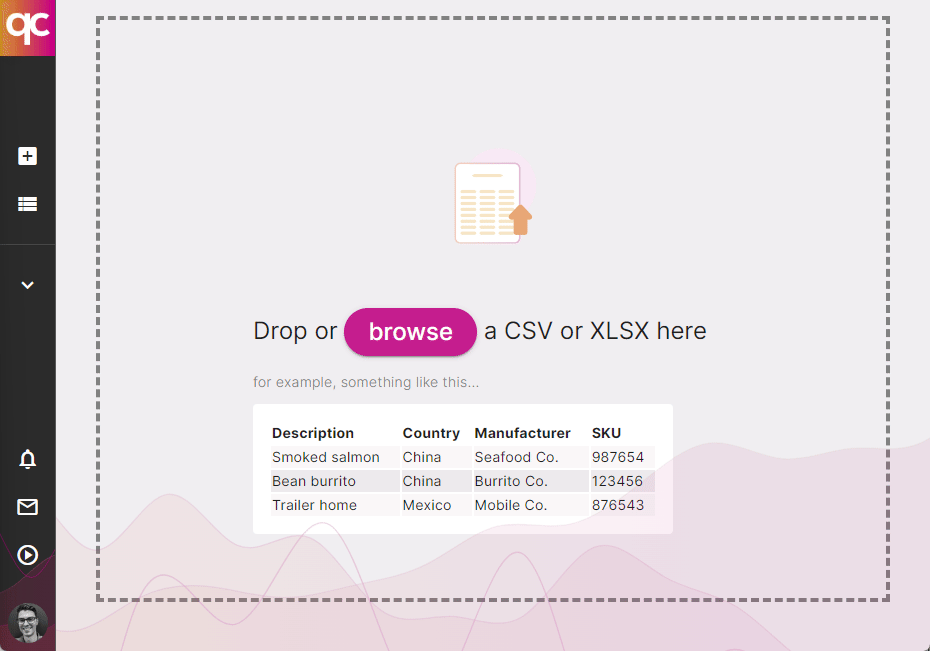
1. Import Your Products
Bring your own spreadsheet — or integrate with your ERP — to synchronize your product catalog with Quickcode. We’ll help you automatically keep things compliant. Book a meeting
2. Run a Compliance Audit
Upload your product catalog, and we’ll run a free compliance audit to find existing risk exposure in your business. Book a meeting
3. Check 301s, PGAs, AD/CVD
Whether it’s out-of-date or bad HS Codes, missing PGAs or ADD/CVD cases, or even missed 301 and other Chapter 98/99 tariffs — Quickcode can help you fix up your existing product catalog, or get a new catalog compliant. Learn more
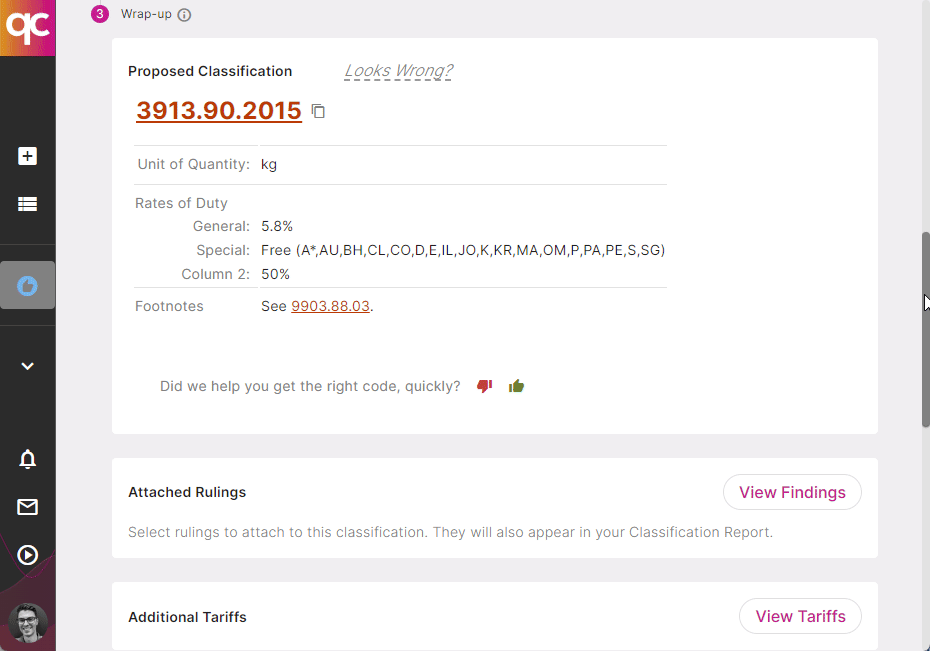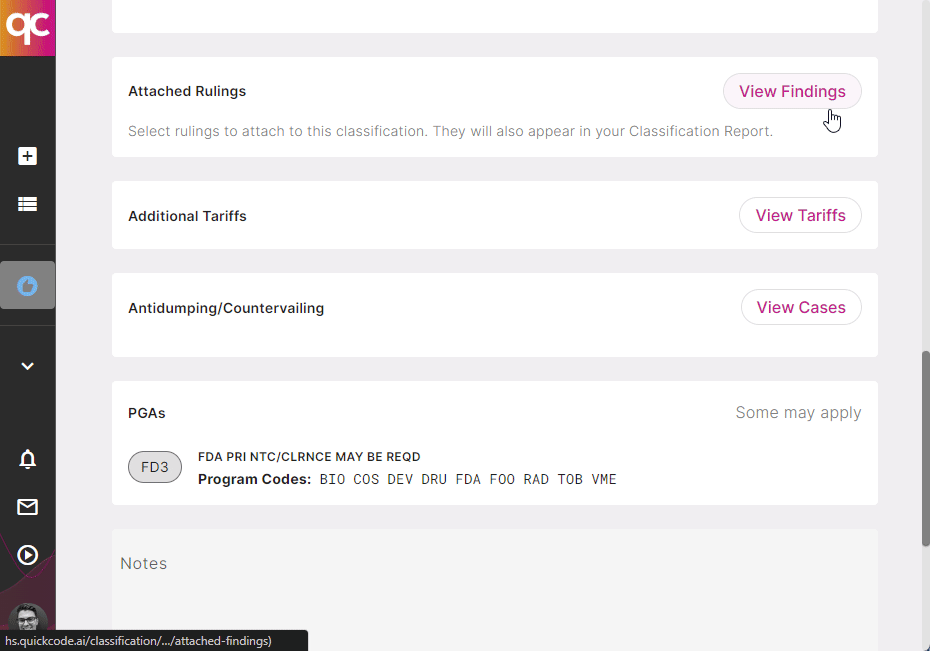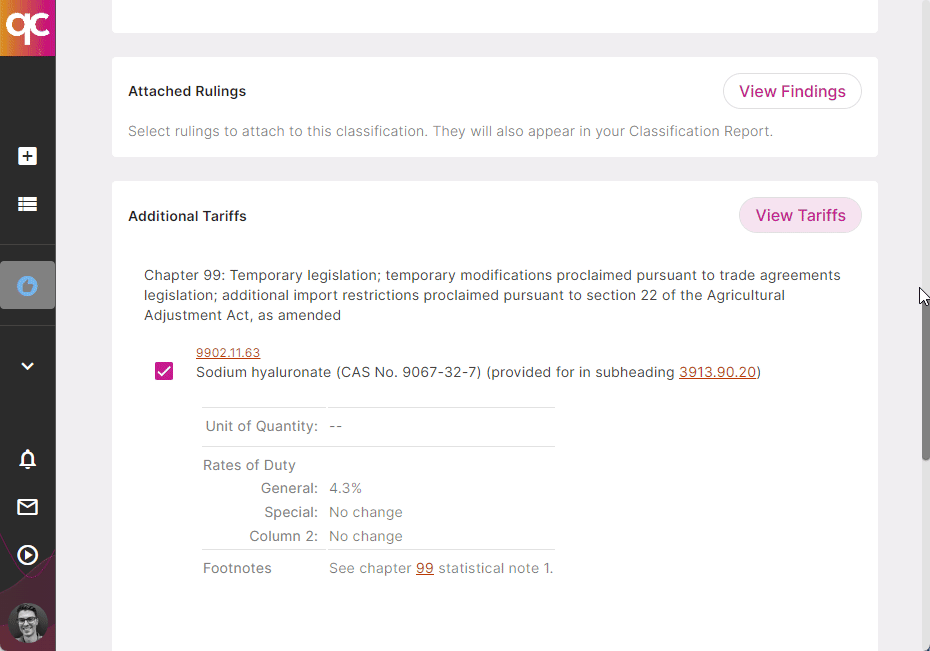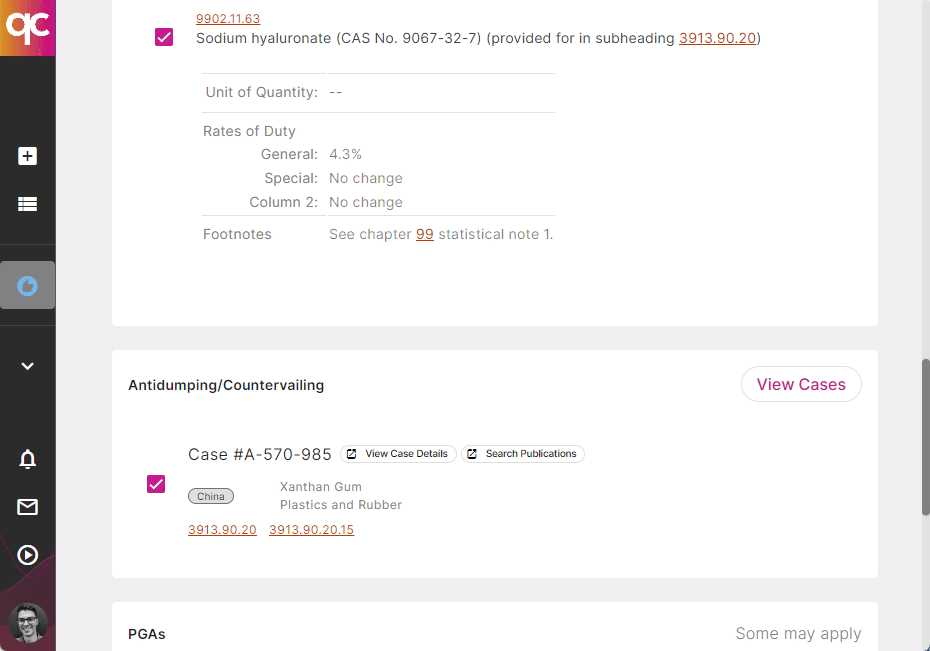
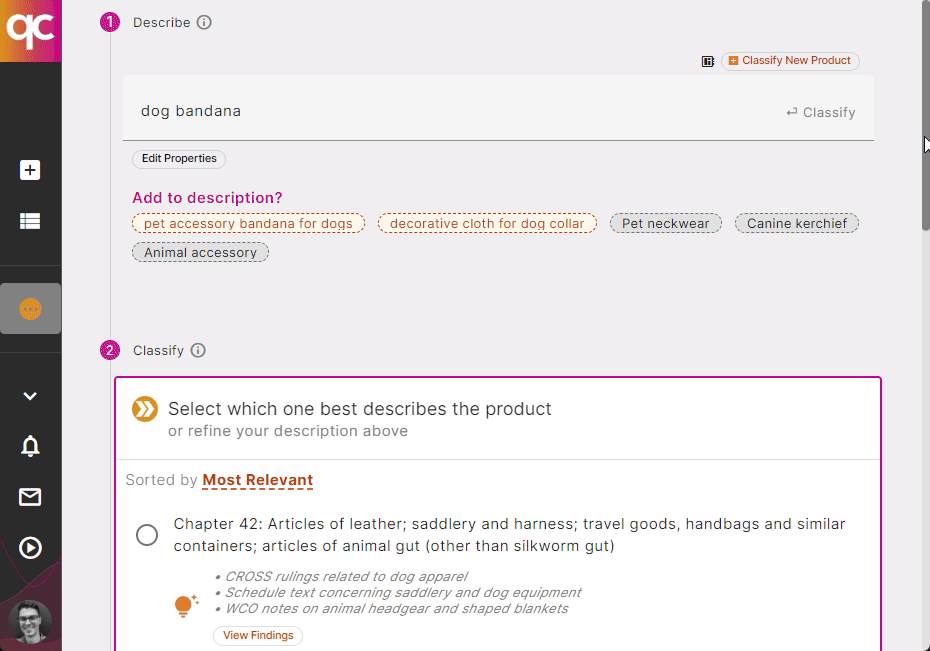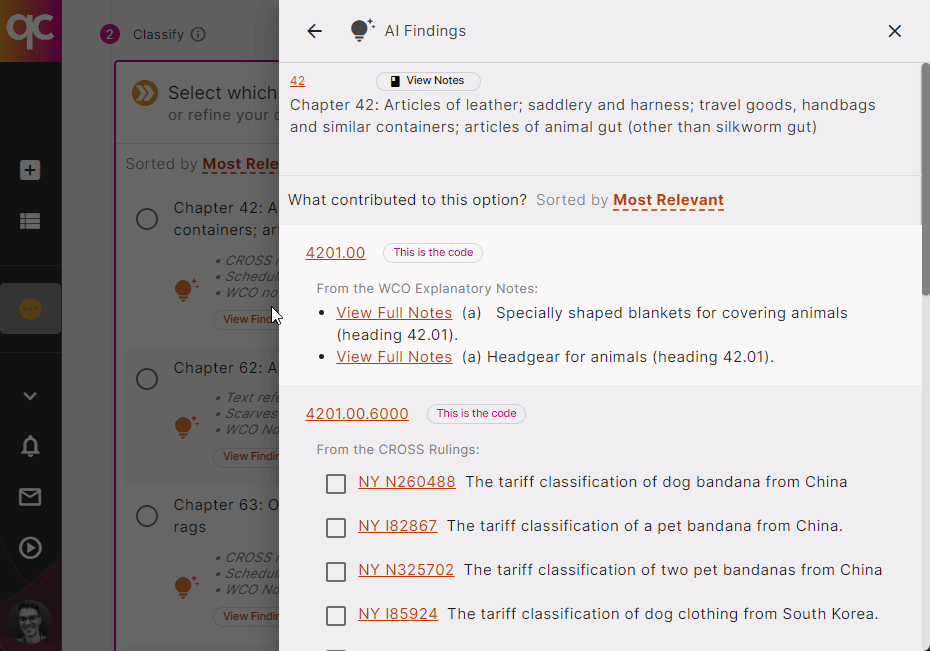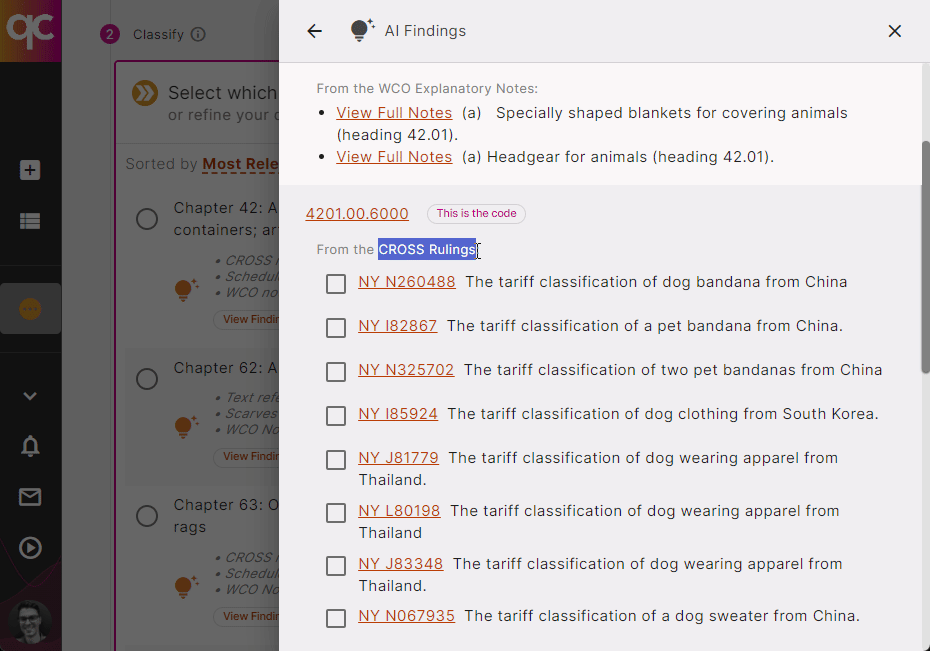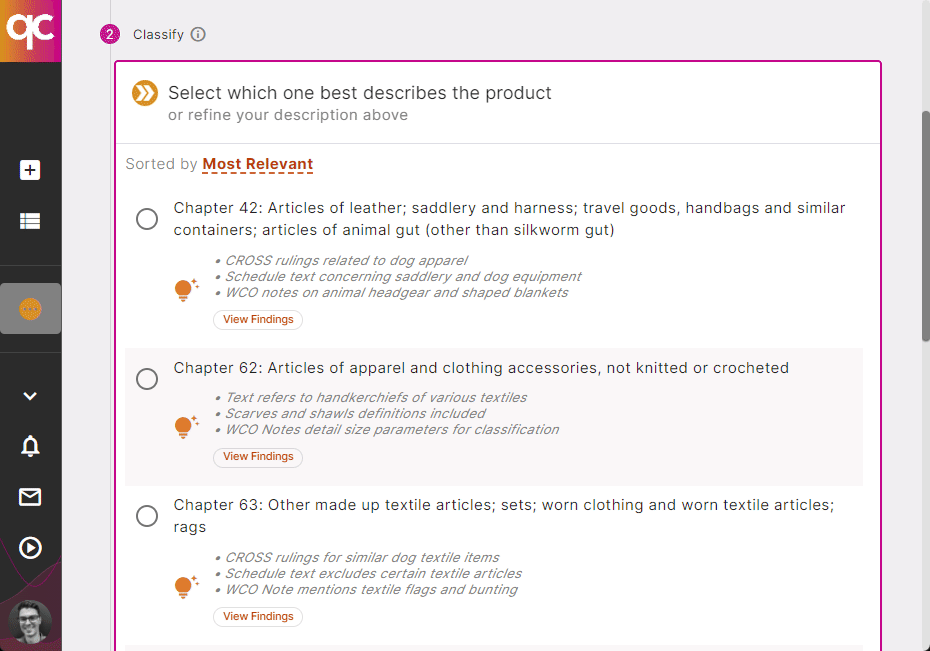
4. Classify with Ease
Quickcode is the only trade compliance tool with explainable AI, bringing all the legal sources you’re used to using for classifications to a single pane. Be amazed at how easy it is to classify new products with full access to the HTS Schedule, CROSS Rulings, WCO Notes, and more, all in one place! Start a 7-day Free Trial
5. Global HS Code Lookup
Need to Classify products beyond the U.S.? Quickcode gives you access to full HS codes and general rates of duty for over 160 countries and jurisdictions. Whether you’re selling into Mexico, importing from Vietnam, or planning a multi-country sourcing strategy, you’ll have the tariff data you need at your fingertips, right alongside your U.S. classifications. Simplify global trade compliance and eliminate time spent searching through foreign customs websites. Learn more
6. 24/7 Trade Compliance Monitoring
Regulations and tariffs are constantly updated. Don’t let your product catalog’s compliance drift — leverage Quickcode to automatically update your compliance data and alert you when manual intervention is needed! Learn more
Recent Tariff Guidance Very shortly after his inauguration, President Trump began rolling out a series of tariffs targeting almost every good that is imported into
As of February 2025, the United States has initiated steps toward implementing a reciprocal tariff policy, aiming to impose tariffs equivalent to those levied by
With recent announcements of new tariffs targeting goods from Canada and China, we know the uncertainty this brings to your trade compliance processes. In this
Simplify trade compliance with Quickcode’s advanced classification tools. Our AI-powered software helps Licensed Customs Brokers and other classification experts quickly identify the correct HS Codes. With up-to-date tariffs, WCO Notes, and CROSS Rulings at your fingertips, you can ensure accuracy and efficiency in your work.
Ensure your product catalog is always compliant and up-to-date with Quickcode for importers. Our AI-driven tool conducts immediate compliance audits, identifies outdated codes, incorrect PGAs, and monitors tariff changes 24/7. Stay ahead of regulatory changes and reduce the risk of costly compliance errors.
AI-Assist is the smart move – read our case studies
Watch Gary King—distinguished Harvard Professor and Quickcode founder—and discover the future of human-in-the-loop programming and how Quickcode is revolutionizing trade compliance with the perfect blend of human intelligence.
Curious about the dynamic relationship between AI and human interaction for importing and exporting? Watch Todd Owen—former CBP executive and a Quickcode board advisor—discuss the pivotal role of AI in optimizing port operations.